데이터/기타
[크롤링] 크롤링 후 엑셀로 저장하기(페이지네이션 크롤링, BeautifulSoup)
성장하기
2023. 7. 16. 16:00
부산 지역에서 개최되는 모든 축제의 기간 대해 분석하고자 한다.
데이터는 많지 않지만 일일히 수기로 입력하기 번거롭기에 크롤링을 통해 축제 이름과 개최 기간을 수집하고, 그 기간을 datetime 객체로 변경해 진행일수를 계산하여 액셀로 저장하였다.
과정은 크게 3단계로 이루어진다.
- url 요청보내서 데이터 받아오기
- Parsing해서 필요한 데이터 추출하기
- Pandas로 엑셀 출력하기
크롤링하고자 하는 페이지는 다음과 같다.
https://www.visitbusan.net/schedule/list.do?boardId=BBS_0000009&menuCd=DOM_000000204012000000&startPage=1&month=0
위 페이지에서 밑줄그은 축제 이름, 기간에 해당하는 부분을 수집한다.

1. urlopen하기
- 필요한 라이브러리 import
- 데이터를 담을 빈 리스트를 만들고, 반복문 구성하기
- 페이지네이션(페이지가 여러개로 구성)이 되어있는 사이트는 페이지 별로 url요청을 보내 데이터를 받아와야한다. 웹사이트에서 끝 페이지가 몇인지 확인하고 파이썬 for loop를 이용해 반복문을 구성하면 간단하게 받아올 수 있다.
- 태그를 선택하는 방법은 아래에서 2가지를 사용했다
- find(), find_all() 메서드 사용하기
- find는 태그명과 속성을 인자로 받아 해당하는 첫번째 태그를 반환한다.
- find_all은 find와 유사하나, 태그를 전부 찾고, 그 자손 요소들까지 전부 찾아 리스트로 반환한다.
- find_all안에 인자를 리스트 형태로 여러개의 태그를 넣어 전부 받을 수 있다.
- css선택자로 찾기
- css 선택자를 이용하여 간편하게 요소 선택을 할 수있다.
- css 선택자는 아래 링크를 참고하길 바란다
쉽게 #id, .class
- find(), find_all() 메서드 사용하기
import urllib.request
from bs4 import BeautifulSoup
import pandas as pd
from datetime import datetime, timedelta
festival_list = []
for page_num in range(1, 5): # 1페이지부터 4페이지까지 있다.
target_url = f'https://www.visitbusan.net/schedule/list.do?boardId=BBS_0000009&menuCd=DOM_000000204012000000&startPage={page_num}&month=0'
resp = urllib.request.urlopen(target_url)
soup = BeautifulSoup(resp, 'html.parser')2. BeautifulSoup으로 Parsing하기
- BeuatifulSoup으로 HTML 텍스트를 Parsing한 후, 요소(HTML 태그)를 선택해 필요한 데이터만 사용할 수 있다.
- 크롤링하고자 하는 페이지에서 개발자도구를 열어(크롬에서 F12) 필요한 요소가 무엇인지 파악한다.
가. 내가 보고자 하는 축제들의 리스트는 playlist라는 id를 가진 ul태그안에 각각의 li태그로 존재한다.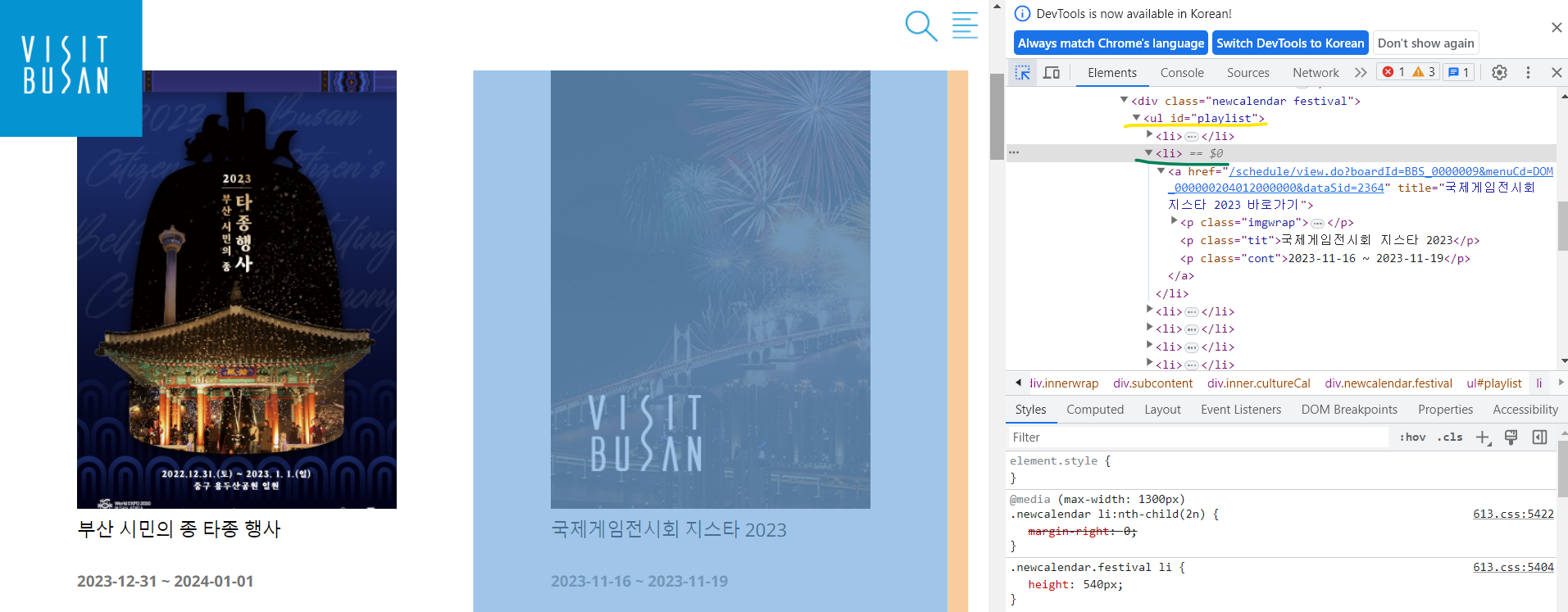
- 개발자 도구 좌측 상단에 마우스를 클릭한 뒤 찾고자 하는 요소에 마우스를 올리면 쉽게 요소를 찾을 수 있다.
내가 필요한 요소
태그명과 클래스명을 알 수 있다. - 나. 축제 이름은 위 '가'항의 li태그 안에 tit 클래스를 가진 p태그에 존재한다.

- 크롤링하고자 하는 페이지에서 개발자도구를 열어(크롬에서 F12) 필요한 요소가 무엇인지 파악한다.
festival_list = []
for page_num in range(1, 5): # 1페이지부터 4페이지까지 있다.
target_url = f'https://www.visitbusan.net/schedule/list.do?boardId=BBS_0000009&menuCd=DOM_000000204012000000&startPage={page_num}&month=0'
resp = urllib.request.urlopen(target_url)
soup = BeautifulSoup(resp, 'html.parser')
playlist = soup.find('ul', id='playlist') # 가. id=playlist인 ul태그 선택
# print(type(playlist))
title_list = playlist.select('.tit') # '가'항에서 선택한 ul태그 내의 나. css 선택자로 tit class를 가진 p 태그 선택
cont_list = playlist.select('.cont') # '나'항과 마찬가지로 기간 텍스트를 포함하는 p태그 선택
# print(len(title_list))
# print(len(cont_list))
for title, cont in zip(title_list, cont_list):
title_dict = dict()
title_dict['title'] = title.text
title_dict['cont'] = cont.text
festival_list.append(title_dict)- 요소들을 수집했으면 dict에 하나씩 넣어 list에 담아준다.
- festival_list

3. Pandas DataFrame으로 만들어 엑셀(.xlsx)파일로 출력하기
- 위에서 이미 dictionary로 만들었기 때문에 DataFrame의 인자로 널어주면 알아서 DF로 잘 변환된다.
- lambda 함수를 이용해 string 형태의 기간을 datetime으로 바꿔주었고, 바꾼 후 기간을 계산해서 일 수로 남겨주었다.
df = pd.DataFrame(festival_list)
# print(df)
df['start_day'] = df['cont'].apply(lambda x : datetime.fromisoformat(x.split(' ~ ')[0]))
df['end_day'] = df['cont'].apply(lambda x : datetime.fromisoformat(x.split(' ~ ')[1]))
df['period'] = df['end_day'] - df['start_day'] + timedelta(days=1)
df['period'] = df['period'].apply(lambda x : str(x).split()[0])
print(df)
df.rename(columns={'title': '축제명', 'cont': '축제기간', 'period': '일수'}, inplace=True)
df.sort_values(by='start_day', inplace=True, ignore_index=True)
df[['축제명', '축제기간', '일수']].to_excel('부산축제.xlsx')- 첫번째로 만든 DataFrame

- 전처리 후 최종 저장한 엑셀 파일

참고
파이썬 크롤링 튜토리얼 - 6 : Pagination 된 게시판 크롤링 | 개발새발 블로그