1. Introduction

- language와는 다르게 vision은 훨신 고차원의 공간을 가지고, 개념들이 쉽게 분리될 수 없다.
- LLM → vision input을 받을 수 있도록 확장되고 있다.
- vision-language 연구가 엄청난 혁신을 가져올 것이다.
- 현재 많은 VLM은 특성이나 순서를 이해하지 못하고, 할루시네이션이 있다.
2. Families of VLM
- contrastive learning
- positive pair → similar representation
- negative pair → different representation
- masking
- text는 그대로 두고, image match를 masking한 후 reconstruction
- image는 그대로 두고, text는 masking한 후 reconstruction
- pre-trained된 LLM과 image encoder를 사용하여 매핑
- generative VLM
- image나 caption을 만들도록 학습
→ 위 3가지 방법은 상호 함께 사용이 가능하다.
2.1. Early work on VLM, based on transformers
- visual-BERT of ViV-BERT → combine text with image tokens
- objective 1) masked modeling, to predict missing part
- objective 2) sentence-image prediction, to predict if a caption is actually describing image
→ attention mechanism으로 단어와 시각 단서간의 관계를 학습
2.2. Contrastive-based VLMs
Energe-based Models
- 발견된 데이터는 low energy, 발견되지 않은 데이터는 high energy 할당
- target distribution은 low energy, 다른 데이터는 high energy를 가질 것임.

- $x^- \sim P_\theta(x)$는 intractable하기에 Markov Chain Monte Carlo로 근사함 → energy를 minimize하는 sample 찾기
Score Matching, Denoising score matching
- input data에 관한 probability density의 gradient만 학습해서 normalization factor를 없앰
Noise Contrastive Estimation
- Self-Supervised Learning, VLM based
- noise distribution $v' \sim P_n(v')$ 에서 샘플링하는 것이 model distribution에서 샘플링하는 것을 잘 근사한다.
- → real distribution sample, noise distribution sample binary classification
InfoNCE
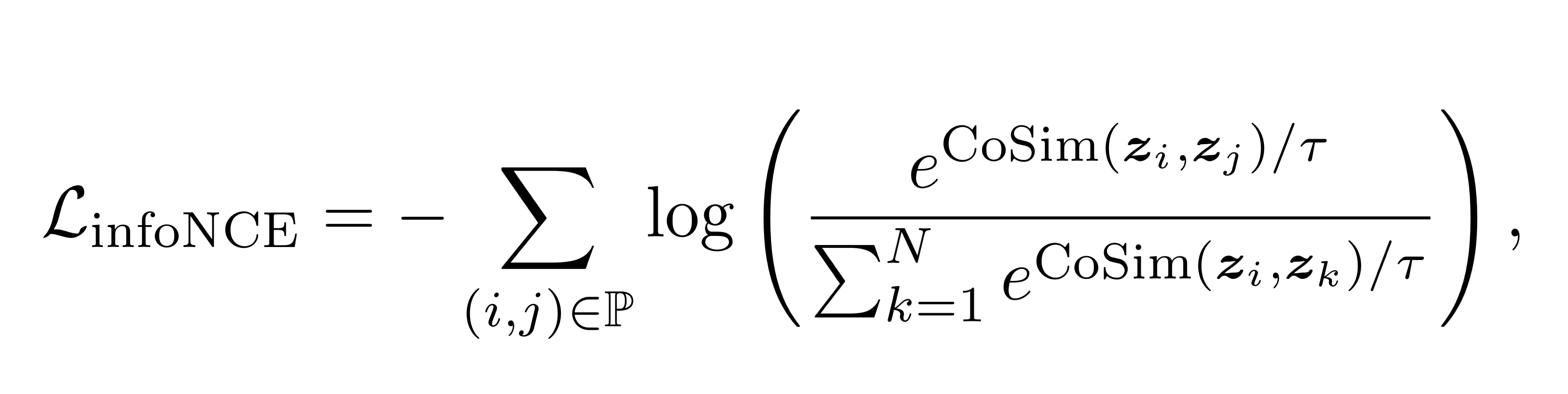
- binary value 대신 representation space에서 distance metric을 사용한다.
- positive pair끼리 거리 계산, negative pair들 끼리의 거리 계산
- representation space에서 가장 가까운 데이터는 가장 유사한 데이터로 예측하도록 학습
- Sim-CLR에서는 한 이미지의 augmented version은 전부 positive pair로 정의, mini-batch 내 다른 이미지는 negative sample로 매칭
- 한계: mini-batch content에 dependent
2.2.1. CLIP
- Positive pair → image, corresponding caption
- Negative pair → same image, 미니배치 내 다른 image의 caption
- image와 text를 같은 space에 encoding함
- Random Initialized된 text, image encoder사용
- SigLIP : InforNCE loss가 아닌 원래 NCE loss(Binary Cross Entropy) 사용
- Llip : cross attention 모듈을 이용해서, text를 image encoding의 condition으로 줌
2.3 VML witch masking objectives
- masking은 transformer 아키텍처에 잘 작동함
- MLM(Masked Language Modeling), MIM(Masked Image Modeling)
- → 이 둘을 조합해서 VLM학습(FLAVA, MaskVLM)
2.3.1 FLAVA
- Foundational Language And Vision Alignment
- 3 component
- Image Encoder : ViT(이미지를 패치로 처리함)
- Text Encoder : Transformer
- Multimodal Encoder : learned linear projection, cross attention module으로 visual, textual information을 통합함
2.3.2 Mask VLM
- pixel space와 text token space에서 직접 마스킹하여 pre-trained vision encoder가 필요하다는 FLAVA의 한계 극복
- 한 모달리티에서 다른 모달리티로의 정보의 흐름이 중요하다.
- 한 모달리티의 reconstruction task는 다른 모달리티로부터 정보를 가져온다.
2.3.3 Information theoretic view on VLM objectives
- VLM으로 쓸모없는 정보를 줄여 rate-distortion 문제를 풀 수 있다.
- 특정 변환을 하는 것은 f(x)를 disjoint한 동등한 class로 나누는 정보를 주입하는 것으로 이해할 수 있다.

- AutoEncoder에서 유의미한 manifold에 매핑하는 것처럼, 유의미한 정보만 보존하는 효과
- 정보이론 관점에서 contrastive loss와 AutoEncoder 둘 다 데이터를 찌그러뜨리는 것이고, 그 비율은 사용된 data transformation에 의해 정의된다.
2.4 Generative-based VLM
- 텍스트, 이미지 생성 관점
- 이미지 캡셔닝을 위한 text encoder & decoder를 만들거나, text와 image를 둘 다 생성할 수 있도록 학습된 모델, text 기반 이미지 생성 모델
- → generate image만을 위해 학습된 모델이라도 vision language task를 풀 수 있다.
2.4.1 text generation
- image encoder output, text decoder로 만든 text representation을 둘 다 input으로 받는 multimodal text decoder를 사용하고 generative loss도 사용하고,
- 이런 multimodal fusion없는 new loss도 사용함
2.4.2 Multi-modal generative model
- image tokenizer 사용: 256x256 이미지를 1024 token으로 만듬
- text tokenizer 사용
- text와 image를 tokenization한다 → decoder-only transformer에 통과시킴
CM3Leon
- Stage1. retrival-augmented pretraining
- CLIP decoder를 dense retriever로 사용하새 관련있고, 다양한 multimodal document를 가져와 input으로 넣는다.
- next token prediction으로 학습
- Stage 2
- SFT, multitask instruction tuning
- text-to-image generation, language-guided image editting 등
Chameleon
- 언어, 이미지가 혼합된 시퀀스를 설명하고 만들 수 있음.
- 처음부터 mixed modal로 디자인된 아키텍쳐
- → fully token based representation이 가능함
- 이미지를 별도의 token으로 바꿈으로써, 각각 text, image encoder가 필요 없어진다. 하나의 transformer만 있으면 됨.
2.4.3 Using generative text-to-image models for downstream vision-language tasks
- generative model을 classification, caption prediction 등 discriminative task에도 사용이 가능함.

- Likelihood estimation with autoregressive model
- discrete한 language와 달리 continuous modality인 image는 토큰을 활용해 autoregressive model을 사용하는 것이 어렵다.
- image tokenizer : 구분된 token의 sequence에 이미지를 매핑($t_1, t_2, \dots, t_k)$
- → image likelihood를 estimation

$p_\theta$ : parameterized by autoregressive VLM이미지 tokenization하는 방법
- VQVAE(Vector Quantised Variational AutoEncoder)
- Vector quantise layer와 함게 VAE를 통과시킴
- VAE : 잘 압축된 continuous representation을 만듬
- VQ : continuous representation → discrete representation에 매핑
- 일반적인 아키텍쳐 : CNN encoder → VQ → CNN decoder
- VQ는 encoder output을 가장 가까운 learned embedding table에 매핑
- pixel space에서 reconstruction loss, codebook commitment loss를 사용해 encoder의 output과 codebook embedding이 가까워지도록 함.
Likelihood estimation with diffusion models

- diffusion은 noise를 예측하므로, density estimation이 어렵다.
- diffusion-based classification technique으로 conditional image likelihood에 대한 variational lower bound를 추정할 수 있다
- → conditional diffusion model을 이용한 classification은 성능은 좋으나 계산이 너무 비싸다.
Advantages of generative classifiers
- “effective robustness” : out-of-distrubution performance가 더 좋음
- test time에 unlabeled example에도 판별 모델과 함께 적응될 수 있으므로, online distribution shift scenario 등에도 사용 가능
2.5 VLMs from pretrained Backbone
- 모델을 밑바닥부터 학습하는 대신 이미 있는 LLM이나 visual extractor를 이용
- text modality와 image modality 사이를 매핑하는 것만 학습해도 된다.
2.5.1 Frozen
- lightweight mapping network를 이용해서 visual feature를 text token embedding에 매핑
- vision encoder와 language model은 frozen
- language model은 inference 때 text and image embedding에 condition 됨
- 새로운 task에 빠르게 적응
- 성능은 보통 수준
2.5.2 Mini GPT
- 최근 트렌드는 image와 text를 input 받아 text를 output으로 내는 multimodal language model을 학습시키는 것
Mini GPT-4
- image representation을 language model의 input space에 align하는 단순한 linear projection layer를 사용
- image encoder와 language model은 pre-trained 되어 있기에 linear projection layer만 학습
Mini GPT-5
- output이 image가 섞인 text일 수 있음
- generative token이라는 special visual token을 사용하여 Stable Diffusion2.1에 사용될 수 있는 feature vector로 매핑
Mini GPT-v2
- image captioning, visual question answering 등 다양한 task를 하나의 interface에서 제공
- task를 구분할 수 있는 identifier를 사용
------------------------------------------------------------------------------------
참고 논문: "An Introduction to Vision-Language Modeling" (Florian Bordes et al., 2024).
출처: [arXiv:2405.17247](https://arxiv.org/abs/2405.17247)
'데이터 > Machine Learning' 카테고리의 다른 글
| [논문 정리]Introduction to VLM(3/3) (1) | 2024.11.24 |
|---|---|
| [논문 정리]Introduction to VLM(2/3) (0) | 2024.11.10 |
| Transformer 기반 모델의 3가지 아키텍처(Encoders, Decoders, Encoder-Decoders)에 대해 알아보자 (1) | 2024.04.14 |
| 한국어 사전학습 ELECTRA + 오픈소스 데이터로 돈안드는 긍부정 분류 모델 만들기 (2) | 2024.02.18 |
| 구글 애널리틱스 로우데이터를 이용해 구매고객 예측모델 만들기(3/3) - SHAP 모델 해석 (0) | 2024.01.07 |


