
- 머신러닝 중 지도학습 방법을 이용해 구매고객 예측 모델을 학습시켜 보겠다.
- 코랩 환경에서 진행하면 별도의 환경설정 없이 머신러닝을 해볼 수 있다.
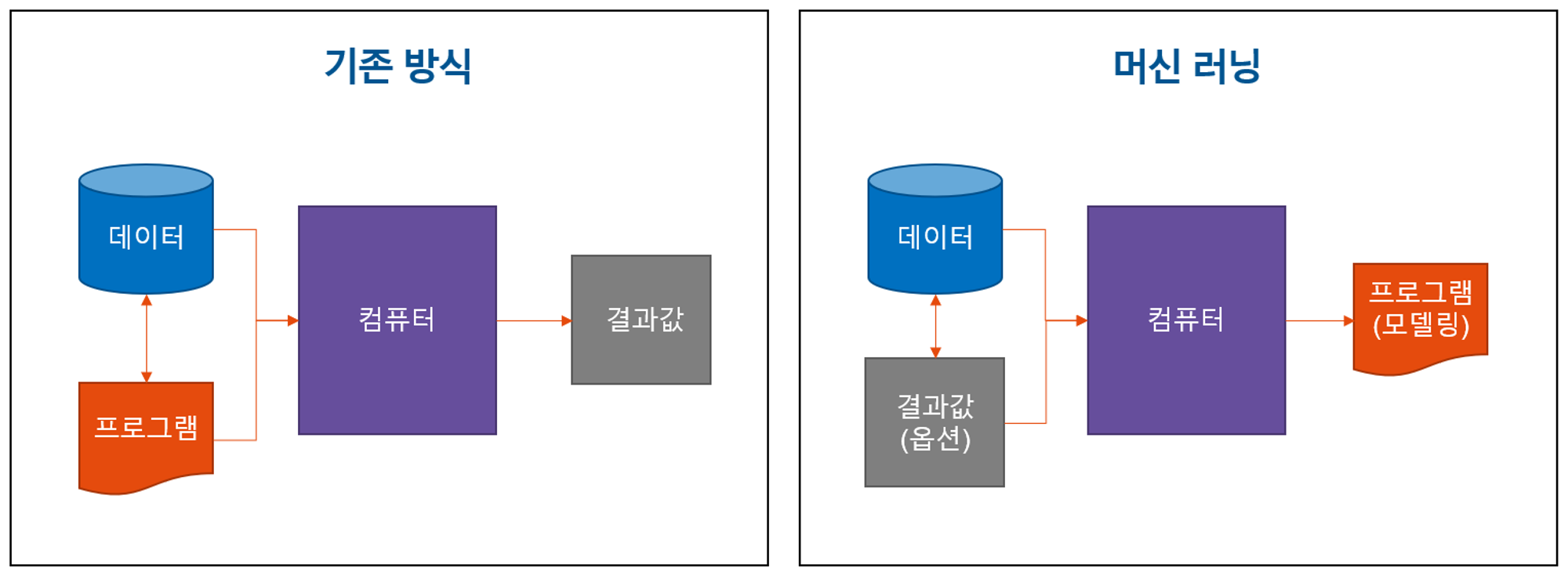
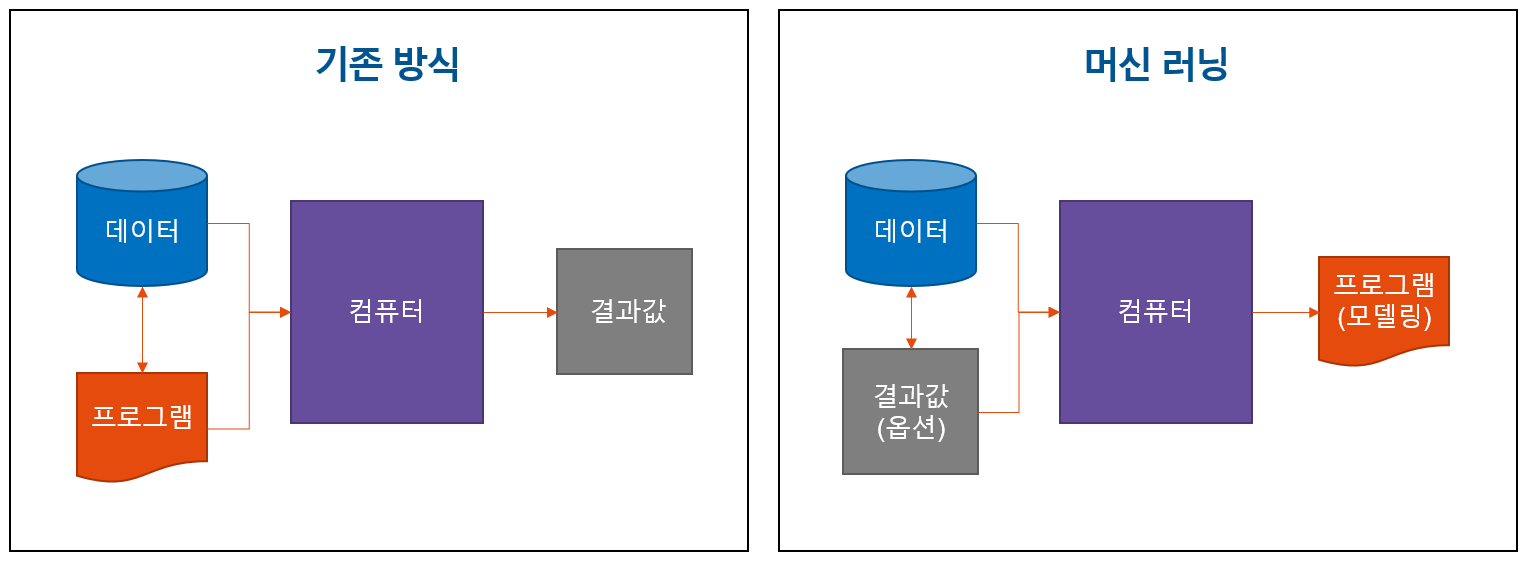
지도학습이란
모델의 입력(input) : x (데이터, 고객들의 속성)
모델의 출력(output) : y (결과값, 고객들의 구매 여부)
- 지도학습이란, 데이터가 주어질 때(x가 주어질 때) y가 발생하는 상황에 대해서, 복잡한 함수 f(x)를 컴퓨터가 학습하는 것
- $y=f(x)$
- x와 y의 관계 f(x)를 알면, 어떠한 x가 들어오더라도 y를 예측할 수 있다!
프로세스
- 학습 데이터셋 불러오기
- 데이터 전처리
- 결측치, 이상치 처리
- Categorical -> Encoding
- Numerical -> Scaling
- 데이터 분배 및 샘플링
- Under Sampling, Over Sampling
- Imbalanced -> balanced
- 모델 학습
- XGBoost
- Evaluation
- metric
- accuracy, recall, presicion, f1_score
- metric
- 모델 저장
- 모델 저장하여 예측으로 사용
1. 학습 데이터셋 불러오기
경로 설정
- 전 게시글()에서 추출한 학습데이터셋을 csv파일로 저장하여, ‘구매고객예측’ 폴더 내 ‘train_data’ 폴더에 넣어 구글드라이브에 업로드 후, 해당 구글 드라이브 ‘구매고객예측’ 폴더의 경로를 file_path에 입력
# 학습 데이터셋 경로 불러오기
# 모듈 import
import pandas as pd
import numpy as np
import os
## 학습데이터셋이 위치한 경로 지정 -> 구글 드라이브 내 경로 (상위 폴더 지정)
## 마우스 우클릭, 경로 복사
file_path = '/content/drive/MyDrive/Colab Notebooks/구매고객예측/' # 복사한 경로를 지정
data_path = file_path + 'train_data/'
data_list = os.listdir(data_path)
data_name = max(data_list)
df = pd.read_csv(data_path + data_name, low_memory=False)
print(data_name)
df['user_pseudo_id'] = df['user_pseudo_id'].astype('object')
df
Feature란?
- Feature란 통계학의 독립변수와 유사한 의미이며 Attribute, 독립변수라고도 불림. 모델의 input으로 들어가 구매 확률을 예측하기 위한 고객들의 속성임
- GA event의 값들로 고객들의 속성을 추출함
- user_pseudo_id : 고객의 식별자. 웹 페이지를 들어올 떄 임시로 부여되는 고객의 unique한 값임. GA 내부 로직으로 user들을 구분하고, 추적함. (Shopify와 식별자 부재로 인해 user의 id 등은 알 수 없고, 현재 user_pseudo_id가 유일한 고객 구분 수단임)
- time_second : 각 이벤트에 존재하는 engagement_time_msec로, event별 소비한 시간을 총 합쳐서 '초'단위로 변환한 변수
- view_item_count : view_item 이벤트(고객이 item을 볼 때마다 이벤트가 생성)의 개수
- view_item_source : view_item 이벤트에서 어떤 경로를 통해 고객이 유입되었는 지를 나타냄(utm파라미터, utm_source)
- view_item_medium : view_item 이벤트에서 어떤 매체를 통해 고객이 유입되었는 지를 나타냄
- view_item_content : view_item 이벤트에서 어떤 컨텐츠를 통해 고객이 유입되었는 지를 나타냄
- first_visit_hour : 첫 방문했을 때, 유입된 시간대를 의미
- device_os : 고객이 사용하는 기기의 운영체제 정보
- device_browser : 고객이 사용하는 기기의 browser 정보
- region : 고객이 접속한 지역(주)
- 각 Feature 설명
Target
- Target, 종속변수, Label은 모델이 맞춰야하는 값이며, 본 머신러닝 모델에서는 구매를 했는 지, 안했는 지를 의미한
- purchase_yn : 구매했으면 1, 구매하지 않았으면 0이며 구매고객과 비구매고객을 구분하는 컬럼
Row, Column
- Row는 표에서 행, 가로방향을 의미하며 각 고객 1명임
- Column은 표에서 열, 세로방향을 의미하며 각 고객의 속성임.
DataFrame
- DateFrame은 각 고객들의 속성을 나열한 '표'로 생각. Python 코드를 통해 간편하게 다룰 수 있게 만들어진 Object임
2. 데이터 전처리
결측치 처리
- 결측치란, 측정되지 않아 빈 값을 의미.
- pandas에서는 NaN으로 표기
- 모델 학습 시 input으로 들어갈 수 없기에 결측치를 제거하거나 대체해야함.
- 본 프로세스에서는 결측치 제거 시 많은 데이터가 유실되기에 적절한 값으로 대체함
결측치 개수 확인
# 결측치 개수 확인
df.isnull().sum()

결측치 대체
- object types => 'Unknown'
- view_item_count => 0
- first_visit_hour => 25
- view_item_page_refferer => 컬럼 삭제
# 원본 dataframe은 df로 메모리에 남겨놓고, df02를 추가 생성해서 결측치를 처리한 dataframe으로 사용
df02 = df.copy()
df02 = df02[['user_pseudo_id', 'last_visit', 'time_second', 'view_item_count', 'view_item_source',
'view_item_medium', 'view_item_content', 'first_visit_hour', 'device_os',
'device_browser', 'region', 'purchase_yn']]
df02['view_item_count'].fillna(0, inplace=True)
df02['view_item_count'].isna().sum()
null_cols = ['view_item_source', 'view_item_medium', 'view_item_medium', 'view_item_content', 'device_os', 'device_browser', 'region']
for null_col in null_cols:
df02[null_col].fillna('Unknown', inplace=True)
# 결측치 개수 확인
df02.isnull().sum()
df02.first_visit_hour.fillna(25, inplace=True)
df02.isna().sum()
이상치 처리
- 이상치란(outlier, anomaly) 보통의 데이터 관측치에서 아주 벗어난, 아주 큰 값 혹은 작은 값을 의미한다.
- 측정 과정의 오류로 발생하기도 하며, 특히 웹 log 데이터는 크롤러 등의 프로그램일 확률 또한 있음.
- 통계치에 왜곡을 주고, 모델의 성능을 저하시킬 수 있으며 학습 데이터 셋에서 제거하는 경우도 있음
- 본 프로세스에서는 수치형 변수 2개 (time_second와 view_item_count)에 대하여 이상치를 확인하였고, time_second의 경우 측정오류 or 프로그램 일 가능성이 높아 제거함
import matplotlib.pyplot as plt
import seaborn as sns
NUM_FEATURES= ['time_second', 'view_item_count']
fig, axes = plt.subplots(ncols=2, figsize=(8, 4))
for i in range(0, 2):
feature = df02[NUM_FEATURES[i]]
sns.boxplot(feature, ax=axes[i])
axes[i].set_title(NUM_FEATURES[i])
fig.suptitle('Numerical Features Boxplot')
plt.show()
- time second의 경우 30000초 이상(500분, 6시간 20분 이상)인 경우 제거
- view_item_count의 경우 max값이더라도, 충분히 가능한 숫자로 판단되어 제거하지 않음

# timesecond는 30000초 이상인 경우 자르기
anomaly_index = df02[df02['time_second'] > 30000].index
df02.drop(anomaly_index, axis=0, inplace=True)
df02.reset_index(drop=True, inplace=True)
Encoding
- 머신러닝 모델은 텍스트를 인식할 수 없음
- 전부 숫자로 바꿔줘야함
- scikit-learn 라이브러리 이용
값 통합
- 범주형 feature 내에서 unique한 값이 너무 많이 발견됨. -> 해당 변수에 속하는 샘플 수가 매우 적어지므로, 모델 성능 저하, 통계적 분석 불가능
- 각 값이 100개 이하의 entity를 가지는 경우 'ETC'로 통합시킴
etc_dict = {}
for col in CATEGORICAL:
count_df = df02[col].value_counts()
etc_list = count_df[count_df <= 100].index.tolist()
etc_list = [i for i in etc_list if i != 'Unknown']
etc_dict.setdefault(col, etc_list)
outlier_list = etc_dict.get(col)
print(col)
print(df02.loc[df02[col].isin(outlier_list), col])
df02.loc[df02[col].isin(outlier_list), col] = 'ETC'
print(col)
print(df02.loc[df02[col]=='ETC', col]) # 전부 ETC로 변환된 것을 확인
불필요한 특수문자 제거
import re
def cleansing_content(text):
text = str(text)
cleaned_text = re.sub('\\\\W', '', text)
return cleaned_text
df02['view_item_content'] = df02['view_item_content'].apply(cleansing_content)
Label encoding
- sklearn에서는 크게 label encoding과 one-hot encoding을 제공한다.
- 트리계열의 모델에서는 one-hot encoding은 성능 저하를 가져오기 때문에 label encoding을 사용하였다.
- inference 이후에 원래 어떤 값을 가졌던 데이터인지 파악하고자 Label Encoder 객체를 pickle파일로 저장하였다.
# Label encoding : 텍스트를 숫자로 변환
from sklearn.preprocessing import LabelEncoder
import pickle
from datetime import date
today = date.today()
today = ''.join(str(today).split('-'))
CATEGORICAL = ['view_item_source', 'view_item_medium', 'view_item_content', 'device_os', 'device_browser', 'region']
for col in CATEGORICAL:
LE = LabelEncoder()
df02[col] = LE.fit_transform(df02[col])
LE_name = f'{col}_LabelEncoder' + f'_{today}'
LE_path = file_path + '/model/' + LE_name + '.pickle'
with open(LE_path, 'wb') as f:
pickle.dump(LE, f)
df02
Scaling
- 숫자형 변수들은 값의 스케일이 다르기 때문에 일치시켜 주었다.
- Multi variable의 경우 스케일이 다르면 특정 변수에 예민하게 반을할 수 있다.
- 정규분포(평균 0, 표준편차 1)의 입력이 최적화 할 때 빠르게 optimal로 갈 수 있도록 도움을 준다고 알려져있다.
- 그러나, tree 기반 모델에는 N(0, 1)로 starndardization하는 것이 별 효과가 없다고 한다.(https://forecastegy.com/posts/does-xgboost-need-feature-scaling-or-normalization/)
from sklearn.preprocessing import StandardScaler
df02['view_item_count'] = df02['view_item_count'].astype('int') # 실수형 -> 정수형 변환
NUM_FEATURES = ['time_second', 'view_item_count']
scaler = StandardScaler()
df02[NUM_FEATURES] = scaler.fit_transform(df02[NUM_FEATURES])
SS_name = f'StandardScaler_{today}'
SS_path = file_path + '/model/' + SS_name + '.pickle'
with open(SS_path, 'wb') as f:
pickle.dump(scaler, f)
df02

3. 데이터 분배 및 샘플링
데이터 분배
- 학습을 위한 Train set과 검증을 위한 Test set을 나눠야함.(보통 7:3, 8:2)
- Trainset으로 검증하는 경우 모델이 답을 외우는 꼴이 되어 모델의 성능이 매우 높게 나옴
- 위 현상을 예방하기 위해 Train, Test set으로 데이터를 나눈 후, Test set은 모델 학습 때 보여주지 않고, 보여주지 않은 데이터로 검증함
- 실제 사용 시, 최근 방문 2주 고객에 대한 예측을 주로 수행할 것이므로, 학습데이터에는 최근 2주 데이터를 제외함
마주한 문제
- 비구매자/구매자의 비율이 99%/1%로 Imbalanced Data임
문제 해결
- 오버샘플링과 언더샘플링을 활용해 비율을 맞출 수 있음
- 모델의 목적을 고려했을 때 비구매자를 잘 찾아내기보단, 구매자를 잘 찾아내는 것이 중요하다 → 구매자에 대한 loss에 가중치를 걸어서 더 잘 맞추도록 함
- 언더샘플링과 오버샘플링으로 비구매자/구매자의 비율을 2:1로 남긴 후(data distribution을 조금이라도 맞추기 위함) 구매자에 대한 weight을 3을 줌.
성능지표
- 성능지표 설정
- 가장 중요한 성능 지표는 1(구매고객)에 대한 recall
- 트레이드오프 현상을 고려하여, accuracy가 90% 이하로 떨어지지 않는 한도 내에서 1에 대한 recall을 올리고자 하였다
- loss 설정
- binary cross entropy를 사용하였다. (가장 binary classification 문제를 잘 풀고, loss에 weight을 줄 수 있는 loss)
샘플링
- 샘플링이란, 전체 데이터 중 일부 데이터만 사용하는 것
- 본 구매 데이터는 비구매자와 구매자의 비율이 약 100:1에 육박함.
- 머신러닝 모델은 성능지표에 의존하여 학습하는데 (틀린 값 == loss, loss를 줄이기 위해 학습), 비구매자의 비율이 높으니 비구매자만 맞춰도 좋은 성능 지표가 나옴(만약 전부 비구매자라고 예측해도 정확도 99%) -> 비구매자만 맞추는 쓸모없는 모델이 나옴
- 따라서 UnderSampling(비구매자의 데이터를 샘플링으로 줄임), OverSampling(구매자 데이터의 약간의 노이즈를 추가하여 구매자 데이터를 늘림) 두가지 기법을 활용하여 데이터의 Balance를 맞추는 사전작업
- train_test_aplit
- (In trainset) Under Sampling
- (In trainset) Over Sampling
# 데이터 분배 (train test split)
from sklearn.model_selection import train_test_split
from datetime import date, timedelta
train_df = df02.copy()
train_df['last_visit'] = pd.to_datetime(train_df['last_visit'], format='%Y%m%d')
last2week = date.today() - timedelta(days=14)
train_df = train_df[train_df['last_visit'] < last2week.strftime(format='%Y-%m-%d')]
FEATURES = ['time_second', 'view_item_count', 'view_item_source', 'view_item_medium', 'view_item_content', 'first_visit_hour', 'device_os', 'device_browser', 'region']
X = train_df[FEATURES]
y = train_df['purchase_yn']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify = y, random_state=0)
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)

샘플링 시 클래스를 1대 1로 맞추지 않은 이유
- 실제 inference 환경에서는 비구매자, 구매자의 imbalanced가 반드시 일어날 것이다. 따라서 조금이라도, 그 비율을 맞추고 싶었다.
모델 학습
- XGBoost라는 모델을 사용하여 학습
- Tabular data에 가장 좋은 성능을 발휘하는 알고리즘 중 하나이기에, Tabular Data 다루면 그냥 XGBoost랑 LGBM부터 테스트하곤 한다.
# 샘플링 기법은 모델의 Pipeline안에 포함시킨다.
from imblearn.pipeline import make_pipeline
from imblearn.under_sampling import RandomUnderSampler
from imblearn.over_sampling import SMOTE
from xgboost import XGBClassifier
xgb = XGBClassifier(n_estimators=1000, objective='binary:logistic', device='cuda', verbose=0,
scale_pos_weight=3, random_state=0)
random_sampler = RandomUnderSampler(sampling_strategy=0.2, random_state=0)
over_sampler = SMOTE(sampling_strategy=0.5, random_state=0)
model = make_pipeline(random_sampler, over_sampler, xgb)
# 학습 하이퍼파라미터 입력
fit_params={"xgbclassifier__early_stopping_rounds":50,
"xgbclassifier__eval_metric" : "auc",
"xgbclassifier__eval_set" : [(X_test, y_test)],
'xgbclassifier__verbose':1}
model.fit(X_train, y_train, **fit_params) # 모델 학습
- 파이프 라인 안에 fit_params 입력 시 객체명 뒤에 언더바(’\\’) 두개 붙여주면 된다.
- sampler들도 파이프라인에 넣어서 학습시킨 이유는, 추후 GridSearchCV로 하이퍼파라미터를 튜닝할 때, 한번 샘플링된 데이터들을 계속 사용하는 것이 아니라, 학습할 때마다 샘플링하여 다양하게 샘플링된 데이터들로 테스트하도록 하였다.
모델 평가
- precision : 모델이 예측한 값 중 실제 값이 적중한 비율(확률)
- recall : 실제 값 중 모델이 옳게 예측한 비율(확률)
- 가장 중요하게 봐야할 것은 1에 대한 recall
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
pred = model.predict(X_test) # 예측
## Classification report
print(classification_report(y_test, pred))
print()
cm = confusion_matrix(y_test, pred, labels=model.named_steps['xgbclassifier'].classes_)
disp = ConfusionMatrixDisplay(confusion_matrix=cm,
display_labels = model.named_steps['xgbclassifier'].classes_)
disp.plot()
plt.show()

---
Reference
https://www.opsnow.com/wp-content/uploads/2023/01/machine_learning_001.png
https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTA9mThzBE5RlPQsFOZ-KGZlfXMZhtjmQul-g&usqp=CAU
https://forecastegy.com/posts/does-xgboost-need-feature-scaling-or-normalization/
'데이터 > Machine Learning' 카테고리의 다른 글
| 한국어 사전학습 ELECTRA + 오픈소스 데이터로 돈안드는 긍부정 분류 모델 만들기 (2) | 2024.02.18 |
|---|---|
| 구글 애널리틱스 로우데이터를 이용해 구매고객 예측모델 만들기(3/3) - SHAP 모델 해석 (0) | 2024.01.07 |
| 구글 애널리틱스 로우데이터를 이용해 구매고객 예측모델 만들기(1/3) - GA 로우데이터 가공 (1) | 2023.12.05 |
| Deep Learning for AI 아티클 요약 (4) | 2023.10.29 |
| sklearn classification_report를 이용한 모델 검증 (0) | 2023.05.21 |



{kind=link}