- 저번 포스트를 통해 구글 애널리틱스 로우데이터를 활용해 머신러닝 모델을 개발해보았다.
- 머신러닝 모델은 단지 성능, 예측력만 중요한 것이 아니다. 예측력이 아무리 좋아도 모델 결과에 대해서 설명할 수 없다면 어떠한 액션도 이끌어 낼 수 없기 때문이다.
- 따라서, 의사결정자가 모델의 결과를 신뢰할 수 있도록, 그리고 구체적인 액션을 취할 수 있도록 돕기 위해 XAI인 SHAP을 이용해 모델 해석을 진행하였다.
XAI
- 정확성이 높은 모델일 수록, 모델의 내부 구조는 복잡하여 내부를 알 수 없다.(==블랙박스)
- XAI(Explanable AI, 설명가능한 인공지능) 이러한 모델을 해석하기 위한 방법론을 이야기한다.
Model-Agnostic method
- 모델 종류에 구애받지 않는 XAI의 방법론을 이야기한다.
- 원래 모델은 블랙박스이므로 모델 내부 변수에 접근하지 않고, input과 output을 조절하면서 변화를 살펴 해석하는 과정이다.
SHAP
- SHAP(SHapley Additive exPlanations)
- Additive란 복잡한 모델 f(x)를 해석이 간단한 모델인 g(x)로 해석을 하는 방법을 의미한다.
- SHAP에서는 변수들을 돌아가면서 해당 변수가 포함된 경우, 포함되지 않은 경우를 포함하는 binary 변수를 이용한 간단한 모델로 원래의 모델을 근사하고자 한다.
Shapley value
- Shapley value란, 어떠한 협동 게임을 할 때, 선수의 기여도를 판단하기 위한 값이다.
- 단순하게 예를 들면, 동일한 축구 경기를 2번 하는데 한번은 손흥민 선수가 포함되어 경기를 했고, 한번은 손흥민 선수 없이 경기를 했다. 이때, 손흥민선수가 있을 때는 3:0 으로 이겼고, 손흥민 선수가 없을 때는 1:0으로 이겼다면 손흥민 선수의 기여도는 2골이라고 볼 수 있다.
(실제 Shapley value를 구할때는, 가능한 모든 조합에 대해서 계산된다. 1인 공조 게임, 2인 공조 게임 ~ 11인 공조 게임 모두 고려함) - 이때, 선수를 포함해서 게임한 경우와 제외하고 게임한 경우의 차이를 Marginal Contribution이라 한다.
- 이 Marginal Contribution의 Weighted average가 곧 Shapley value이다.
- 이 shapley value를 이용하여 feature를 선수로 가정하고, 경기 결과(상금)을 모델의 output으로 가정하여 모델을 해석하는 모델이 SHAP 이다.
- SHAP은 python 라이브러리로 구현되어 있어 간단히 구현할 수 있다. https://shap.readthedocs.io/en/latest/
SHAP 해석
- 이전 글을 확인해보면 알겠지만, 본 모델은 XGBoost 모델을 이용하였다.
- XGBoost의 output은 구매/비구매 log odds ratio이므로, 이 해석 결과에서 Shapley value는 변수가 있을 때와 없을 때의 log odds ratio 차이의 weighted average라고 생각을 하면 쉽다.
- 즉 나이브하게 생각해서 shapley value가 음수이면 구매 확률을 낮추는데 기여하는 변수이고, 양수이면 구매확률을 높이는 데 기여하는 변수라고 생각하면 된다.


- time_second의 범위가 넓다는 것은 time_second를 사용하지 않고 예측한 것과 사용하고 예측한 것의 차이가 크다.
- 즉, 모델의 성능은 time_second의 영향을 많이 받는다.
- 빨간색, 파란색은 모델의 예측 결과가 아닌 해당 feature의 value다.
- time_second변수에 대한 shapley value가 높을 때, feature의 색도 빨간색이므로 time_second도 높다. -> time_second가 높을 때, 구매확률도 높다.
- SHAP value가 0보다 낮다. → 방향, 음의방향으로 기여한다.
- 0보다 크다 → 양의 방향으로 기여한다.
- SHAP을 해석할 때 주의할 점은, 변수와 모델 결과에 인과관계를 부여하면 안된다는 점이다. 단지 변수를 포함하고 예측했을 때, 변수를 포함하지 않고 예측했을 때의 차이라는 것을 기억한 채 모델을 해석해야한다.
가장 중요한 변수 time_second 해석
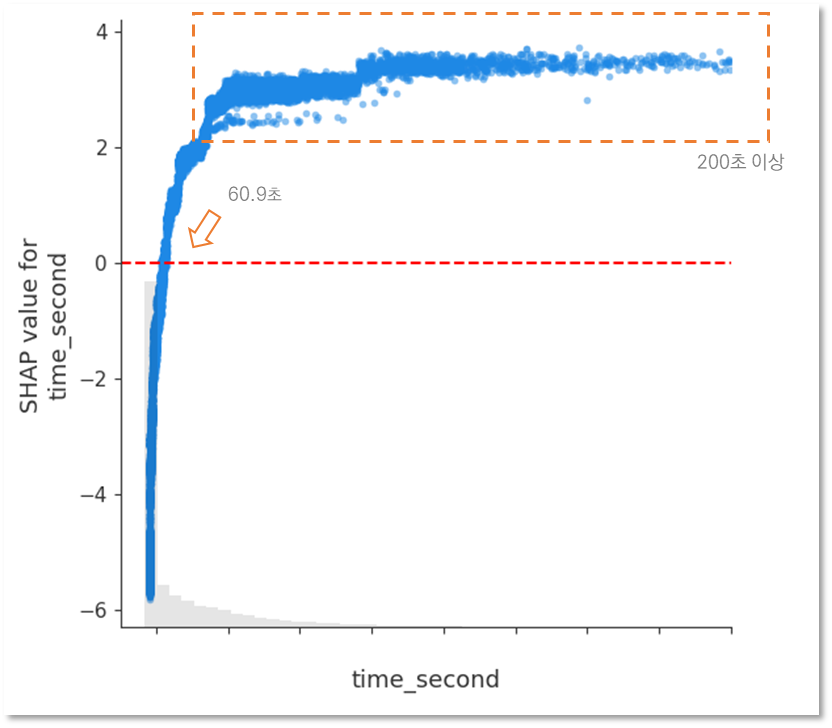
- time_second는 늘어날 수록, 구매확률의 증가에 기여한다.
- 그러나 선형적으로 늘어나지 않고, 일정 수준만큼 늘어난 이후에는 크게 늘어나지 않는다.
- 0이 되는 최소값 : 60.9초
- 60.9초 미만 머문 사람은 소비 시간이 구매 확률에 부정적인 기여를 한다.
- 60.9초 이상 머문 사람은 소비 시간이 구매 확률에 긍정적인 기여를 한다.
- 안정적으로 shap value가 2이상이 나와 구매 확률에 긍정적인 기여를 하는 시점은 200초 이상 머물렀을 때 부터이다.
모델 해석 결론
구매 단계에서 관련있는 고객의 행동은 머무는 시간과, 고객이 본 item의 개수다.
본 AI 모델의 결과를 토대로, 구매단계를 최적화해야한다. (구매를 유도하기 위해 고객들이 머무는 시간을 증가시키고, 여러 item을 보도록 할 수 있다.)
관심있을 법한 연관상품을 노출시키는 등의 전략으로 머무는 시간과 보는 상품을 늘릴 수 있다.
Reference
https://shap.readthedocs.io/en/latest/
https://www.youtube.com/watch?v=NF6kk8QkiHE
'데이터 > Machine Learning' 카테고리의 다른 글
| Transformer 기반 모델의 3가지 아키텍처(Encoders, Decoders, Encoder-Decoders)에 대해 알아보자 (1) | 2024.04.14 |
|---|---|
| 한국어 사전학습 ELECTRA + 오픈소스 데이터로 돈안드는 긍부정 분류 모델 만들기 (2) | 2024.02.18 |
| 구글 애널리틱스 로우데이터를 이용해 구매고객 예측모델 만들기(2/3) - 모델 학습 (1) | 2023.12.23 |
| 구글 애널리틱스 로우데이터를 이용해 구매고객 예측모델 만들기(1/3) - GA 로우데이터 가공 (1) | 2023.12.05 |
| Deep Learning for AI 아티클 요약 (4) | 2023.10.29 |


